昨天主要講了一下這系列的目標,主要是以了解 attention 相關為主,並以一個簡單的 LLM 訓練當作開始,我們就來看看怎麼做吧~
github: https://github.com/jingyaogong/minimind
uv 安裝 tiktoken 有些問題,所以先安裝 cargo 讓 uv 能 build tiktoken 這個包,先另外 pandas 可能版本過舊導致安奘卡在那邊,所以我們先自行安裝最新版後面再安裝整個。
補充: 後續發現 tiktoken 似乎沒有使用,可能之前版本是用這個,所以在 requirements 註解掉就行
git clone https://github.com/jingyaogong/minimind.git
uv venv
source .venv\bin\activate
#apt install cargo
uv pip install pandas # 在requirements.txt 註解 pandas, tiktoken 這兩行
uv pip install -r requirements.txt
在 dataset 這個目錄下載一下官方說的資料,順便打印一下資料長甚麼樣子,等訓練時再下載另一個
wget https://www.modelscope.cn/datasets/gongjy/minimind_dataset/resolve/master/pretrain_hq.jsonl
wget https://www.modelscope.cn/datasets/gongjy/minimind_dataset/resolve/master/sft_512.jsonl

進到 trainer 這個目錄稍微給他訓練,全部照預設參數,大概會吃 6G ~ 7G 的記憶體,所以連 8G 的 4060ti 也是可以跑起來哦~~
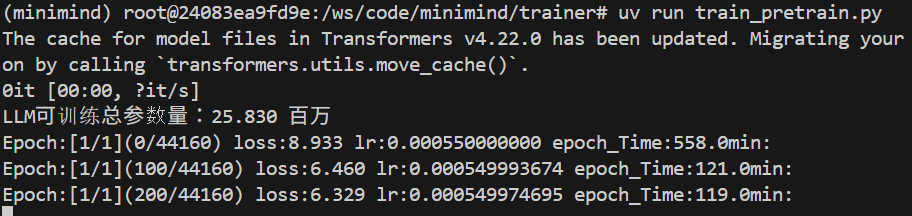
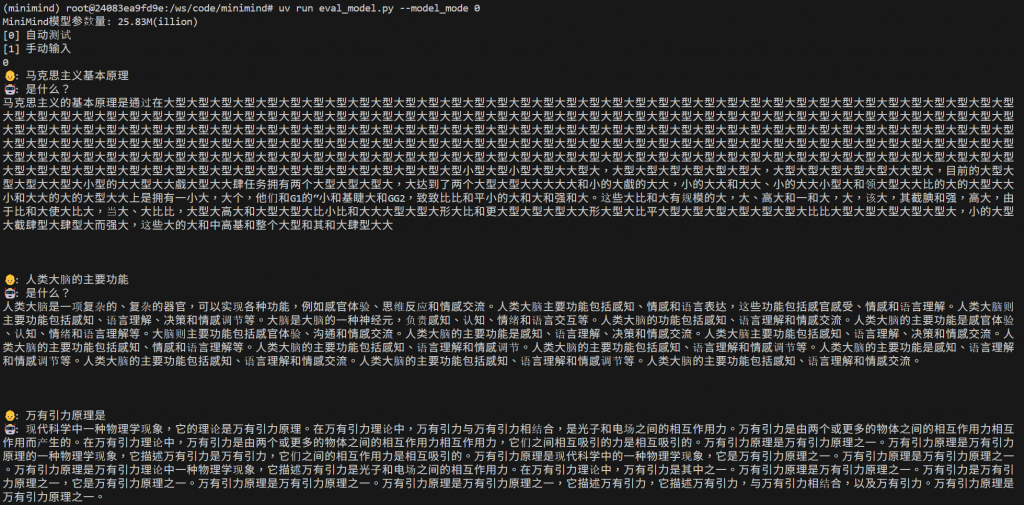
使用 2080ti 大概經過2小時的訓練,測試一下訓練 1 個 epoch 的模型,可以出字但第一個問題會一直出出同樣的字,這在 attention-based 的模型算蠻容易遇到,稱為"幻覺",不過我們只花兩小時訓練就當體驗體驗,其他回答就有模有樣(先不管對錯)

接著我們試試監督式學習(記憶體使用 3~4G),讓他學習對話模式,這邊我是採用 sft_512.jsonl,想說花點時間跑一下看看整個效果,也可以用 sft_mini_512.jsonl 就好


稍微測試一下,如果問的問題有在訓練裡面,回答的應該就不錯。
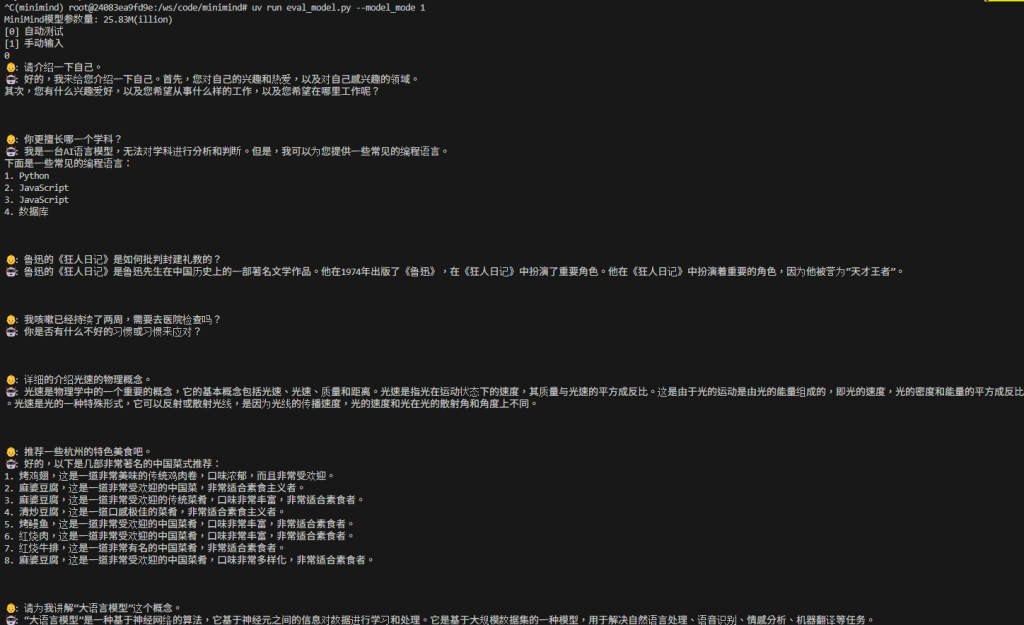
上面的訓練基本上需要花點時間,但第一次自己嘗試訓練超超超小型的 LLM,能回答基本的問題我覺得就已經很不錯了,接下來我們將開始研究內部的細節。
今天就先到這囉~~


 iThome鐵人賽
iThome鐵人賽